Nacos源码学习计划-Day18-配置中心-集群-集群节点间如何同步配置信息
ZealSinger 发布于 阅读:253 技术文档
那么单点上的配置中心的比较核心的几个功能我们基本都介绍过了,今天我们看看集群环境的配置中心的相关功能的实现。
还是一样的,当我们将Nacos从单点变为集群模式,我们会需要处理哪些问题:
-
集群中节点配置修改,节点内如何同步的?
-
对应的目标节点接收到同步数据后如何刷新配置的?
所以这一节我们从“集群节点间配置信息的同步”这个点探讨Nacos源码
配置文件变更发布源码分析
确认源码入口
当我们使用Nacos自带的管理端的时候,我们可以在配置管理中进行配置的修改和发布。
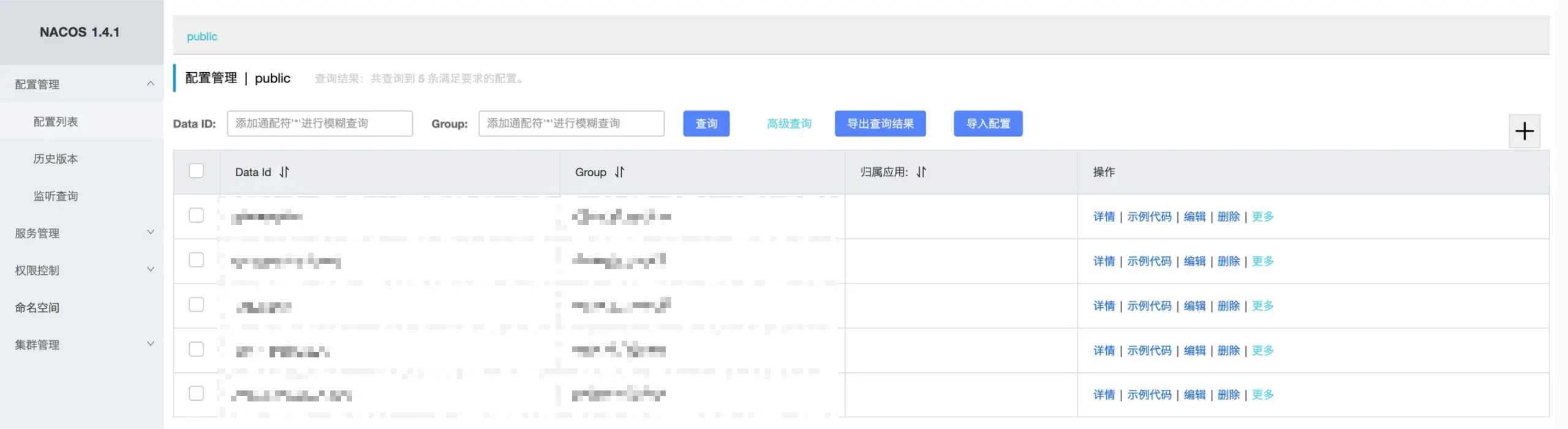
在这个模块当中,有配置列表,可以维护我们的配置文件,并且编辑配置文件客户端可以及时地感知变化,并且刷新配置文件,在通知客户端的时候,也会通知集群节点进行数据同步。当我们编辑发布成功之后,我们可以在历史版本中找到我们发布的记录,并且还支持回滚的操作。
我们思考一下,当我们点击 确认发布 按钮,Nacos 需要做几件事?大概的猜想是:
-
修改配置文件记录;
-
保存历史表;(看到这里有没有想起来上一节中我们提到过的
addRefreshRecord方法,或许和这个的逻辑有关呢?) -
通知客户端监听事件进行配置文件变更;
-
通知集群客户端文件变更。
我们可以利用F12,找到Nacos管理端进行配置发布的时候,对应的HTTP请求的接口,从而准确定位到代码Controller入口
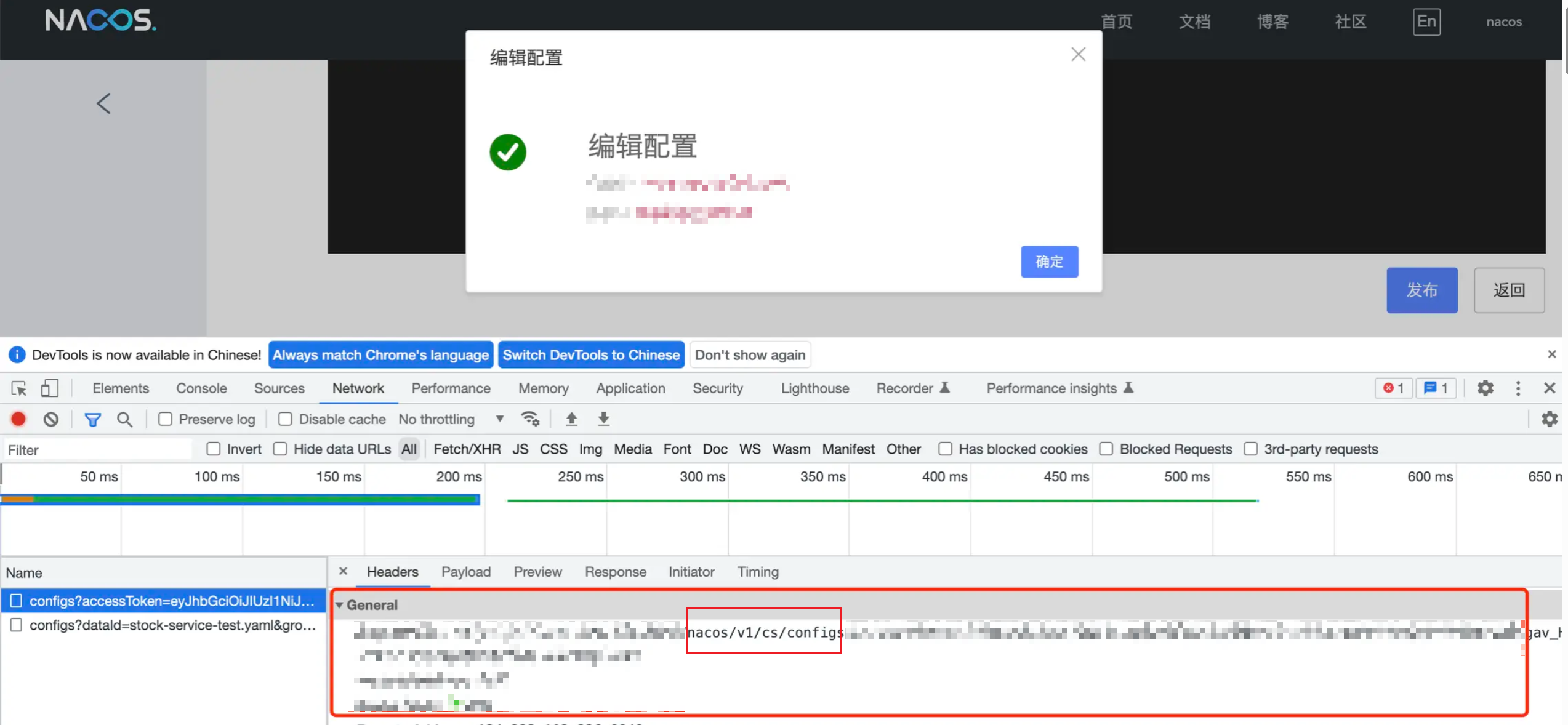
通过F12的请求内容,可以很方便确定到最终的Controller入口代码如下
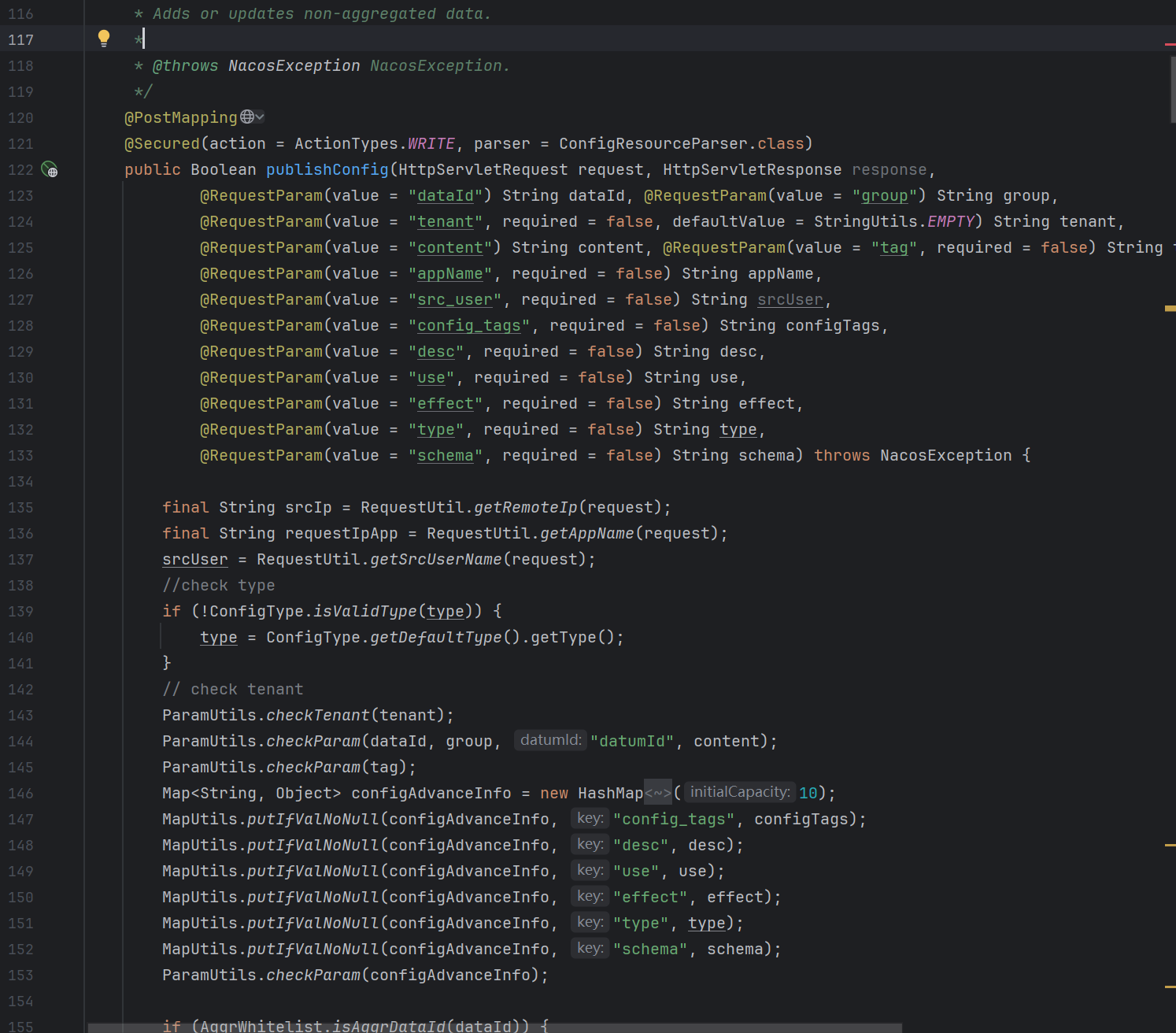
分析
代码稍微有点多,我们没必要全看,下面的代码对源码进行了删减
(action = ActionTypes.WRITE, parser = ConfigResourceParser.class)
public Boolean publishConfig(HttpServletRequest request, HttpServletResponse response,
(value = "dataId") String dataId, (value = "group") String group,
(value = "tenant", required = false, defaultValue = StringUtils.EMPTY) String tenant,
(value = "content") String content, (value = "tag", required = false) String tag,
(value = "appName", required = false) String appName,
(value = "src_user", required = false) String srcUser,
(value = "config_tags", required = false) String configTags,
(value = "desc", required = false) String desc,
(value = "use", required = false) String use,
(value = "effect", required = false) String effect,
(value = "type", required = false) String type,
(value = "schema", required = false) String schema) throws NacosException {
final String srcIp = RequestUtil.getRemoteIp(request);
final String requestIpApp = RequestUtil.getAppName(request);
// ..... 都是一些入参的封装校验 .....//
// 这里的if区分逻辑暂且不需要看
if (StringUtils.isBlank(betaIps)) {
if (StringUtils.isBlank(tag)) {
// 可以看到无论走到哪个if条件中 都会走如下两个方法 知识传入的参数不填一样罢了
// 新增配置或者修改配置
persistService.insertOrUpdate(srcIp, srcUser, configInfo, time, configAdvanceInfo, true);
// 配置变更事件
ConfigChangePublisher
.notifyConfigChange(new ConfigDataChangeEvent(false, dataId, group, tenant, time.getTime()));
} else {
persistService.insertOrUpdateTag(configInfo, tag, srcIp, srcUser, time, true);
ConfigChangePublisher.notifyConfigChange(
new ConfigDataChangeEvent(false, dataId, group, tenant, tag, time.getTime()));
}
} else {
// beta publish
persistService.insertOrUpdateBeta(configInfo, betaIps, srcIp, srcUser, time, true);
ConfigChangePublisher
.notifyConfigChange(new ConfigDataChangeEvent(true, dataId, group, tenant, time.getTime()));
}
ConfigTraceService
.logPersistenceEvent(dataId, group, tenant, requestIpApp, time.getTime(), InetUtils.getSelfIP(),
ConfigTraceService.PERSISTENCE_EVENT_PUB, content);
return true;
}可以看到,核心的两个方法persistService.insertOrUpdate() 和 ConfigChangePublisher.notifyConfigChange,所以我们可以来分析这两个方法
insertOrUpdate方法
这个方法来自于PersistService接口,该接口有如下两种实现类,这个方法因为是配置的保存和更新,涉及到了存储部分,而我们之前有提到过,Nacos在单机和集群配置下,前者使用的嵌入式的Derby数据库,而后者是可以使用遵循JDBC的多种三方数据库,所以两者的逻辑肯定是不一样的,也正是如此,insertOrUpdate也就有如下两个实现类
EmbeddedStoragePersistServiceImpl:这个实现类是 Nacos 内置的 Derby 数据库。
因为这个数据库我们没怎么接触过,所以我们这里简单过一下,不会进行深入讨论
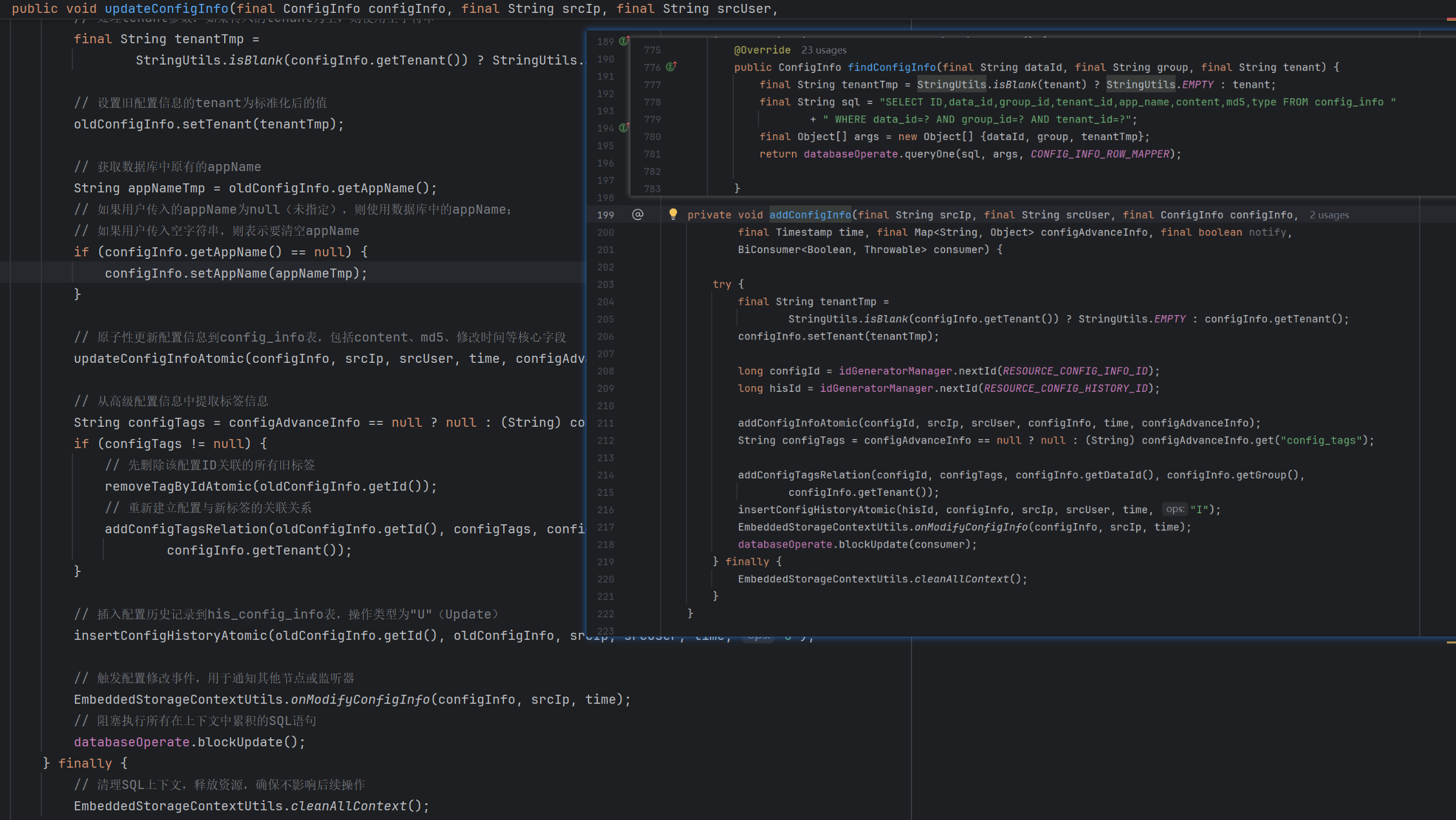
利用findConfigInfo方法查找是否存在这个接受到的配置信息,如果存在则调用更新逻辑即updateConfigInfo方法;反之如果不存在为null的话,则调用新增逻辑即addConfigInfo方法

这里提到的findConfigInfo方法 和 updateConfigInfo方法 和 addConfigInfo方法的逻辑如下,整体内容和Derby数据库的操作相关
ExternalStoragePersistServiceImpl:这个实现类是对应外置的数据库。我们一般使用MySQL。

首先可以看到,在这个的实现中,和Derby的操作有些许不一样,在内置数据库的操作下,我们是通过findConfigInfo方法查找是否存在当前配置,而在ExternalStoragePersistServiceImpl 的实现中,我们并没有调用这个findCOnfigInfo这个方法,而是通过try-catch这种异常捕获的方式进行区分的
public void insertOrUpdate(String srcIp, String srcUser, ConfigInfo configInfo, Timestamp time,
Map<String, Object> configAdvanceInfo, boolean notify) {
try {
addConfigInfo(srcIp, srcUser, configInfo, time, configAdvanceInfo, notify);
} catch (DataIntegrityViolationException ive) { // Unique constraint conflict
updateConfigInfo(configInfo, srcIp, srcUser, time, configAdvanceInfo, notify);
}
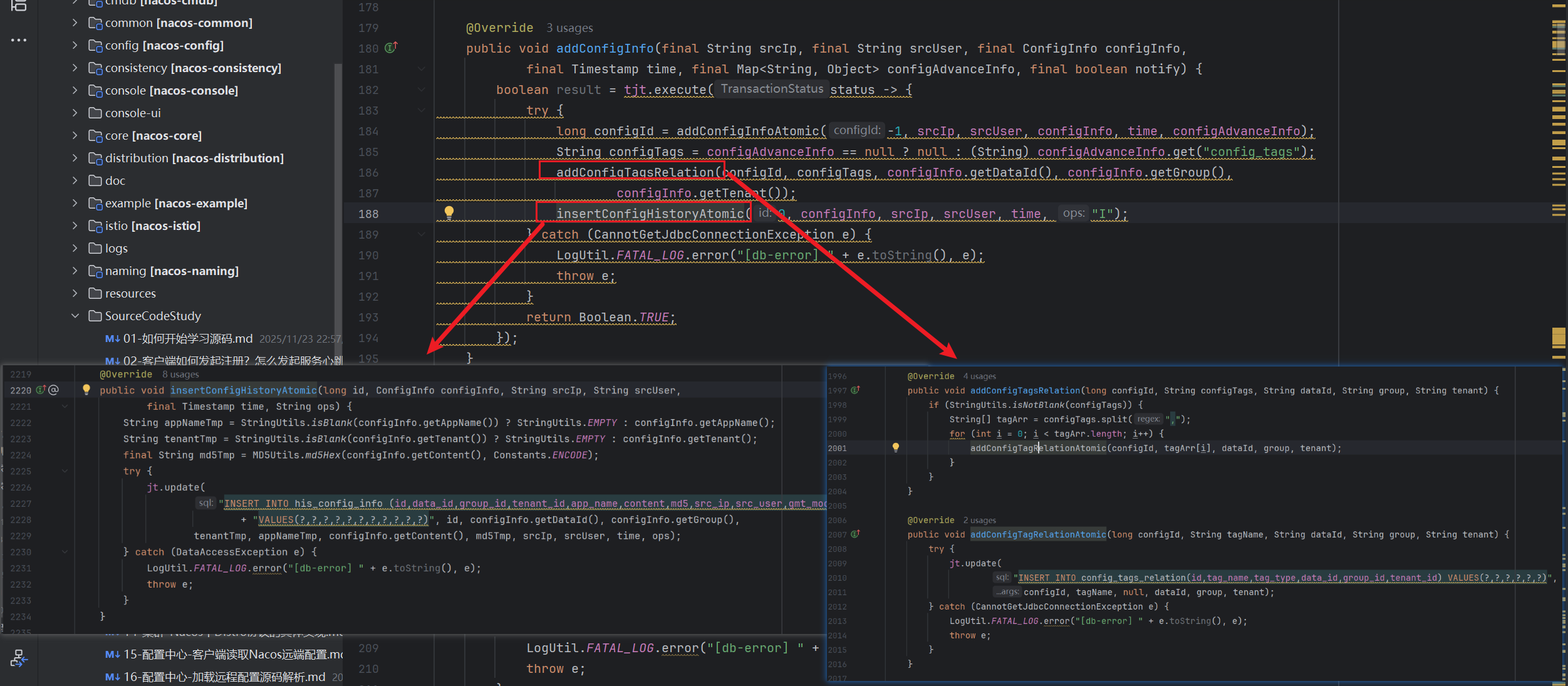
}我们进一步看一下addConfigInfo方法和updateConfigInfo的底层逻辑,可以看到这个方法起始主要逻辑就是addConfigTagsRelation方法和insertConfigHistoryAtomic方法
public void addConfigInfo(final String srcIp, final String srcUser, final ConfigInfo configInfo,
final Timestamp time, final Map<String, Object> configAdvanceInfo, final boolean notify) {
boolean result = tjt.execute(status -> {
try {
long configId = addConfigInfoAtomic(-1, srcIp, srcUser, configInfo, time, configAdvanceInfo);
String configTags = configAdvanceInfo == null ? null : (String) configAdvanceInfo.get("config_tags");
addConfigTagsRelation(configId, configTags, configInfo.getDataId(), configInfo.getGroup(),
configInfo.getTenant());
insertConfigHistoryAtomic(0, configInfo, srcIp, srcUser, time, "I");
} catch (CannotGetJdbcConnectionException e) {
LogUtil.FATAL_LOG.error("[db-error] " + e.toString(), e);
throw e;
}
return Boolean.TRUE;
});
}主要逻辑我们不多看了,大致看一下,就是通过这两个方法进行添加数据库的操作,前者是tag标签表的相关操作,捕获CannotGetJdbcConnectionException;后者是记录配置的变更历史,捕获DataAccessException异常,两者都是直接使用JDBCTemplate进行数据库的操作,而我们最外层的insertOrUpdate方法捕获的DataIntegrityViolationException属于DataAccessException子类,主要是对于记录配置变更的时候唯一键异常的捕获,也就是利用数据库的唯一键,当确定此操作在数据库中存在的时候,就认定不是insert而是update
我们再来看看updateConfigInfo这个方法
public void updateConfigInfo(final ConfigInfo configInfo, final String srcIp, final String srcUser,
final Timestamp time, final Map<String, Object> configAdvanceInfo, final boolean notify) {
boolean result = tjt.execute(status -> {
try {
// 查询老的配置数据
ConfigInfo oldConfigInfo = findConfigInfo(configInfo.getDataId(), configInfo.getGroup(),
configInfo.getTenant());
String appNameTmp = oldConfigInfo.getAppName();
if (configInfo.getAppName() == null) {
configInfo.setAppName(appNameTmp);
}
// 更新配置数据
updateConfigInfoAtomic(configInfo, srcIp, srcUser, time, configAdvanceInfo);
String configTags = configAdvanceInfo == null ? null : (String) configAdvanceInfo.get("config_tags");
if (configTags != null) {
// delete all tags and then recreate
removeTagByIdAtomic(oldConfigInfo.getId());
addConfigTagsRelation(oldConfigInfo.getId(), configTags, configInfo.getDataId(),
configInfo.getGroup(), configInfo.getTenant());
}
// 保存到历史数据表
insertConfigHistoryAtomic(oldConfigInfo.getId(), oldConfigInfo, srcIp, srcUser, time, "U");
} catch (CannotGetJdbcConnectionException e) {
LogUtil.FATAL_LOG.error("[db-error] " + e.toString(), e);
throw e;
}
return Boolean.TRUE;
});
}
在 updateConfigInfo() 方法中,我们能很直观地看到做三件事情,先是查询了对应的配置,然后更新配置,最后是保存到历史表当中去。在这三个方法中,我们可以跟进去看一看,里面就能看到对应的 sql 语句,以 findConfigInfo() 方法为例,代码如下:
public ConfigInfo findConfigInfo(final String dataId, final String group, final String tenant) {
final String tenantTmp = StringUtils.isBlank(tenant) ? StringUtils.EMPTY : tenant;
try {
return this.jt.queryForObject(
"SELECT ID,data_id,group_id,tenant_id,app_name,content,md5,type FROM config_info WHERE data_id=? AND group_id=? AND tenant_id=?",
new Object[]{dataId, group, tenantTmp}, CONFIG_INFO_ROW_MAPPER);
} catch (EmptyResultDataAccessException e) { // Indicates that the data does not exist, returns null.
return null;
} catch (CannotGetJdbcConnectionException e) {
LogUtil.FATAL_LOG.error("[db-error]
、" + e.toString(), e);
throw e;
}
}
notifyConfigChange方法
分析完insetOrUpdate()的逻辑可以看到,其方法逻辑是完全做完了数据库的相关操作的,那么很明显,notifyConfigChange()的作用就是用来通知客户端和其他集群节点。
我们可以一直点机notifyConfigChange()方法查看,会发现最后是到了DefaultPublisher类下的publish()方法,其方法逻辑很简单,其实就是将传入的event放入到了内部的BlockingQueue<Event>类型的queue成员
public boolean publish(Event event) {
checkIsStart();
boolean success = this.queue.offer(event);
if (!success) {
LOGGER.warn("Unable to plug in due to interruption, synchronize sending time, event : {}", event);
receiveEvent(event);
return true;
}
return true;
}从我们看Nacos源码经验来看,大伙儿肯定一下子就能反应出来,这肯定就是一个异步任务队列,事实上也是的,还是老规矩,分析异步任务队列就应该从其放任务和取任务两个地方进行分析,我们这里很明显就是放任务,那么我们利用Idea搜索一下取任务的逻辑
可以看到就是在DefaultPublisher这个类下的openEventHandler()方法内进行的任务拿取,而openEventHandler方法就是在run方法内被调用,也就是说一直在获取和消费这个队列中的任务
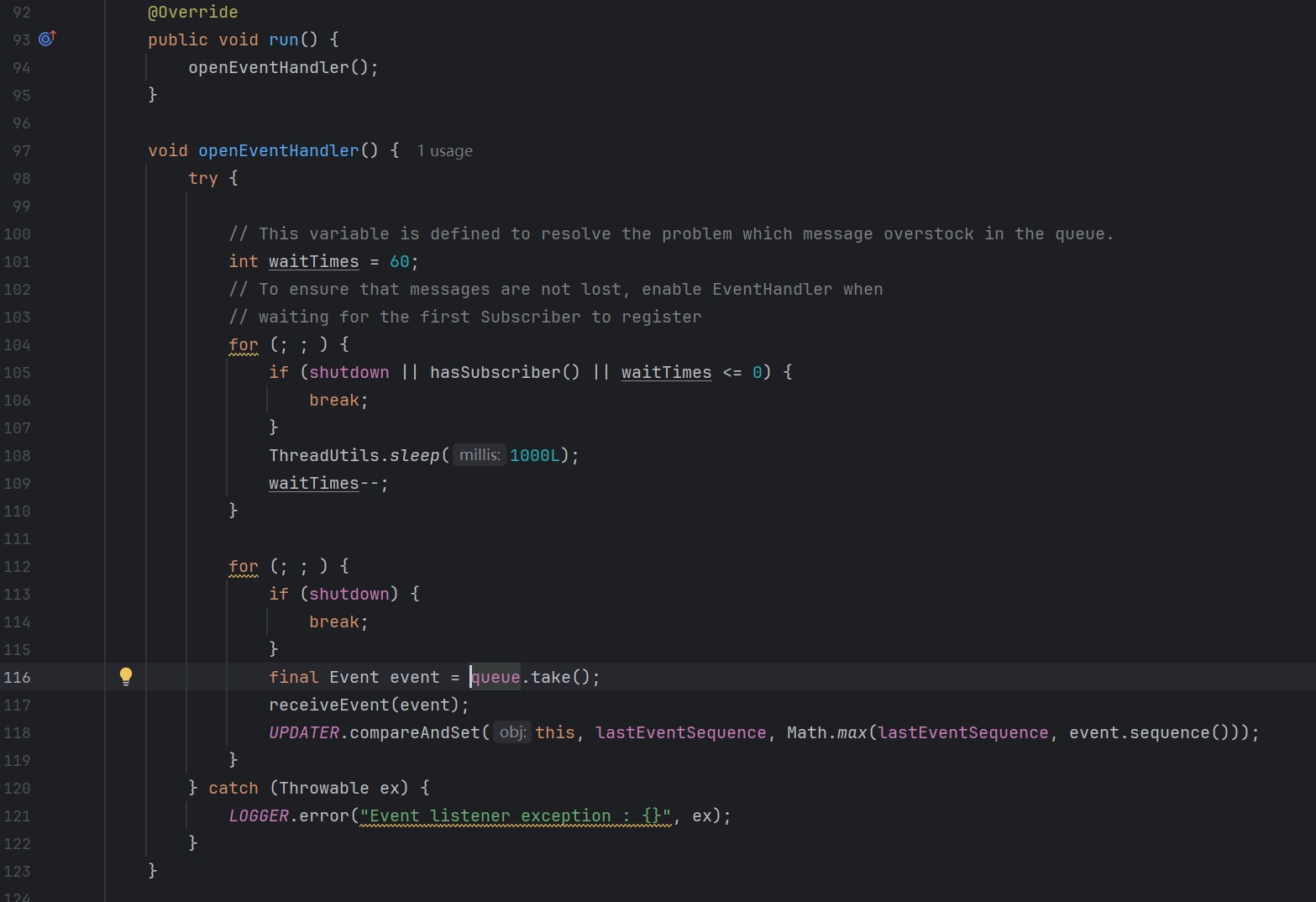
来看一下,从队列中获取到的event被receiveEvent(event)方法消费,该方法的逻辑为
void receiveEvent(Event event) {
// event.sequence()是一个Event类的static类型的AutomicLong类型的数据,即一个静态的线程安全的Long类型,用于记录事件的处理序号,每处理一个Event都会+1
final long currentEventSequence = event.sequence();
// 循环通知监听事件
for (Subscriber subscriber : subscribers) {
// 如果对应的事件监听者忽略该类型的事件 或者 当前序列号小于记录的最新序列号(代表当前事件是一个过期的事件,为了保证事件处理的顺序性,过期消息不予处理)
if (subscriber.ignoreExpireEvent() && lastEventSequence > currentEventSequence) {
LOGGER.debug("[NotifyCenter] the {} is unacceptable to this subscriber, because had expire",
event.getClass());
continue;
}
// 通知
notifySubscriber(subscriber, event);
}
}
public void notifySubscriber(final Subscriber subscriber, final Event event) {
LOGGER.debug("[NotifyCenter] the {} will received by {}", event, subscriber);
final Runnable job = new Runnable() {
public void run() {
// 核心点在这里
subscriber.onEvent(event);
}
};
final Executor executor = subscriber.executor();
if (executor != null) {
executor.execute(job);
} else {
try {
job.run();
} catch (Throwable e) {
LOGGER.error("Event callback exception : {}", e);
}
}
}
可以看到notifySubscriber方法的逻辑就是将Event的处理封装为一个线程任务交给线程池去执行,那我们看看这个onEvent()方法中如何处理的
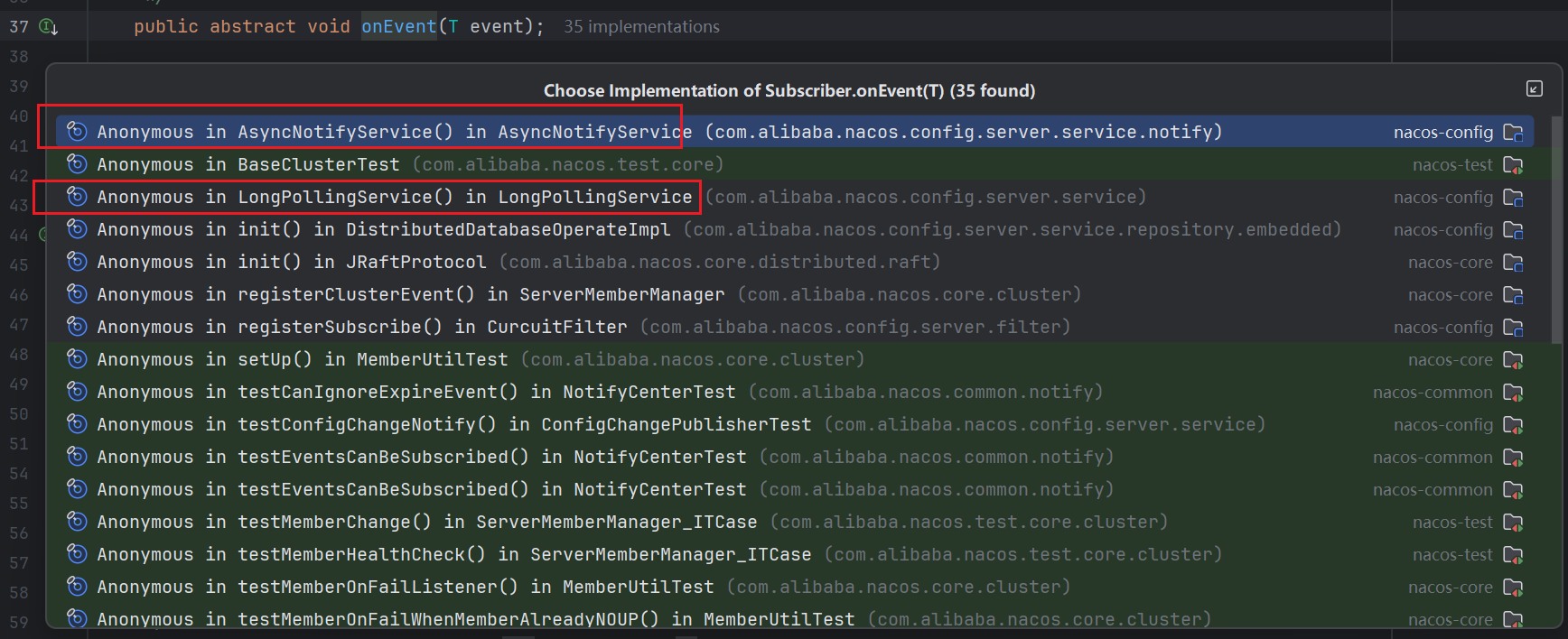
可以看到onEvent()是源自于Subscriber这个抽象类,其底层的实现有点多,我们主要关注我框起来的两个(其实不要我框,大家看一下所属的类名,就大致能猜到作用BaseClusterTest肯定是一个测试性质的;DistributedDatabaseOperateImpl肯定和DB的操作监听有关;JRaftProtool肯定和之前聊过的Raft协议有关 )
-
AsyncNotifyService:通知集群节点进行数据同步的订阅者。 -
LongPollingService:通知客户端配置文件变更的订阅者。
集群节点进行数据同步
发起同步逻辑
我们先来看看AsyncNotifyService中对于onEvent()方法的实现
public void onEvent(Event event) {
// 配置中心数据变更 同步其他集群节点数据
if (event instanceof ConfigDataChangeEvent) {
ConfigDataChangeEvent evt = (ConfigDataChangeEvent) event;
long dumpTs = evt.lastModifiedTs;
String dataId = evt.dataId;
String group = evt.group;
String tenant = evt.tenant;
String tag = evt.tag;
// 获取集群列表 注意 这里包括了自己 没有排除子节点
Collection<Member> ipList = memberManager.allMembers();
// In fact, any type of queue here can be
Queue<NotifySingleTask> queue = new LinkedList<NotifySingleTask>();
// 遍历集群列表同步数据
for (Member member : ipList) {
// 把任务添加到队列当中
queue.add(new NotifySingleTask(dataId, group, tenant, tag, dumpTs, member.getAddress(),
evt.isBeta));
}
ConfigExecutor.executeAsyncNotify(new AsyncTask(nacosAsyncRestTemplate, queue));
}
}获取我们的集群列表,然后遍历添加任务到 queue 队列当中,然后统一提交异步任务:AsyncTask,那我们关心的还是这个异步任务的 run() 方法,代码如下:
/**
* Runnable接口的run方法实现,作为任务执行的入口,触发异步调用逻辑的执行
*/
@Override
public void run() {
// 调用核心的异步任务执行方法,处理集群数据同步任务
executeAsyncInvoke();
}
/**
* 核心方法:异步执行集群数据同步任务,循环消费队列中的同步任务并处理
*/
private void executeAsyncInvoke() {
// 循环从任务队列中获取待处理的集群数据同步任务,队列为空时终止循环
// 队列中存储的是需要同步到其他集群节点的NotifySingleTask任务对象
while (!queue.isEmpty()) {
// 从队列头部取出一个集群数据同步任务(FIFO原则)
NotifySingleTask task = queue.poll();
// 获取当前任务需要同步的目标集群节点IP地址
String targetIp = task.getTargetIP();
// 检查目标IP对应的节点是否属于当前Nacos集群的有效成员(是否在集群配置列表中)
if (memberManager.hasMember(targetIp)) {
// 判断目标集群节点的健康状态:是否处于不健康状态且需要延迟处理
boolean unHealthNeedDelay = memberManager.isUnHealth(targetIp);
if (unHealthNeedDelay) {
// 若目标节点不健康,记录通知事件日志(类型为节点不健康)
// 日志内容包含配置数据标识(dataId/group/tenant)、最后修改时间、本机IP、事件类型等关键信息
ConfigTraceService.logNotifyEvent(
task.getDataId(), // 配置项ID
task.getGroup(), // 配置分组
task.getTenant(), // 配置租户(用于多租户隔离)
null, // 扩展参数(此处无)
task.getLastModified(), // 配置最后修改时间戳
InetUtils.getSelfIP(), // 本机IP地址
ConfigTraceService.NOTIFY_EVENT_UNHEALTH, // 事件类型:节点不健康
0, // 事件耗时(初始为0)
task.target // 目标节点标识
);
// 将不健康节点的同步任务重新放入异步执行队列,延迟重试(避免频繁无效调用)
asyncTaskExecute(task);
} else {
// 若目标节点健康,构建HTTP请求头,准备发送同步请求
Header header = Header.newInstance();
// 添加请求头参数:配置最后修改时间(用于目标节点校验数据版本)
header.addParam(NotifyService.NOTIFY_HEADER_LAST_MODIFIED, String.valueOf(task.getLastModified()));
// 添加请求头参数:发起同步操作的本机IP(用于目标节点溯源)
header.addParam(NotifyService.NOTIFY_HEADER_OP_HANDLE_IP, InetUtils.getSelfIP());
// 若当前任务是Beta配置同步,添加Beta标识头参数
if (task.isBeta) {
header.addParam("isBeta", "true");
}
// 添加认证相关头信息(如token、身份标识等),保证请求合法性
AuthHeaderUtil.addIdentityToHeader(header);
// 通过REST模板发送HTTP GET请求,将配置数据同步到健康的目标节点
// 参数说明:
// - task.url:目标节点的同步接口地址
// - header:构建好的请求头
// - Query.EMPTY:无URL查询参数
// - String.class:响应数据类型为字符串
// - AsyncNotifyCallBack(task):异步回调处理器,处理请求结果(成功/失败逻辑)
restTemplate.get(task.url, header, Query.EMPTY, String.class, new AsyncNotifyCallBack(task));
}
}
// 若目标IP不属于集群有效成员,直接跳过该任务(无需处理)
}
}
在配置文件变更之后,会通过发布事件的机制来通知其他集群节点进行数据同步,最后还是通过 HTTP 的方式,请求的地址是/v1/cs/communication/dataChange,那最后我们一起来看下,其他集群节点收到配置数据同步的请求之后,具体是怎么做的。
被同步节点的处理
通过URL很容易找到对应的Controller,可以看到,整体逻辑就是从请求中获取封装的数据,然后根据isBetaStr调用dump()不同重载版本
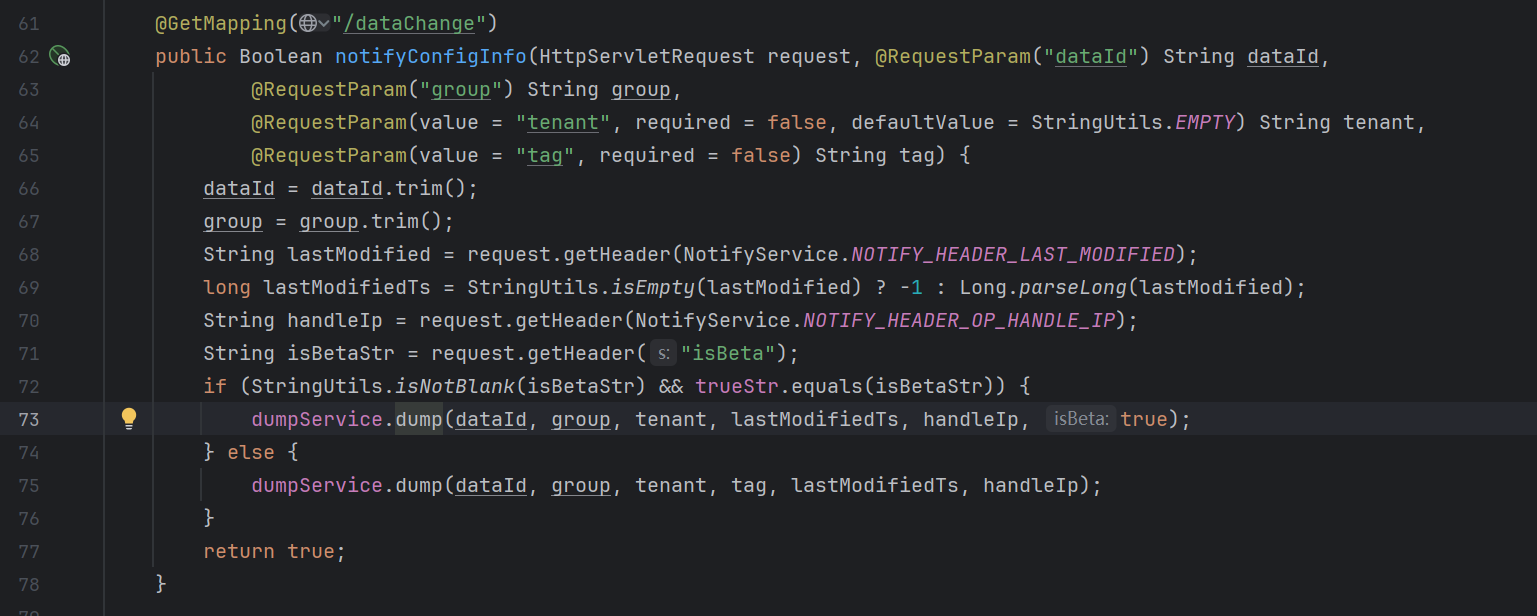
dump()的逻辑中最后调用的dumpTaskMgr.addTask()方法,该方法的最后实现在NacosDelayTaskExecuteEngine类中的addTask()方法
/**
* 添加任务到执行引擎。
*
* 这个方法的主要作用是:
* 1. 使用可重入锁(ReentrantLock)确保线程安全,防止并发添加任务时出现数据不一致
* 2. 检查是否已存在相同key的任务:
* - 如果存在旧任务,则调用newTask.merge(existTask)方法将旧任务的信息合并到新任务中
* 这样可以保留之前任务的一些状态信息,避免丢失重要数据
* 3. 将新任务(可能已合并)存入tasks这个ConcurrentHashMap中,key作为任务的唯一标识
* 4. 使用finally块确保锁一定会被释放,即使发生异常也能正常解锁
*
* 典型使用场景:
* - 当需要延迟执行某个任务时,通过此方法注册任务
* - 如果同一个key的任务被多次添加,会进行合并而不是简单覆盖,保证任务状态的连续性
*
* @param key 任务的唯一标识键
* @param newTask 要添加的延迟任务对象
*/
@Override
public void addTask(Object key, AbstractDelayTask newTask) {
lock.lock(); // 获取锁,保证线程安全
try {
// 尝试获取已存在的同key任务
AbstractDelayTask existTask = tasks.get(key);
if (null != existTask) {
// 如果存在旧任务,将旧任务的状态合并到新任务中
newTask.merge(existTask);
}
// 将新任务(可能已合并)放入任务集合中
tasks.put(key, newTask);
} finally {
lock.unlock(); // 释放锁,确保其他线程可以访问
}
}
从这里可以看到,这里最后就是将Task放入到tasks这个内部的Map中了,看到这里可能大家已经忘了,我们在09-集群-新增微服务实例那一篇中,讲到Nacos利用双层内存队列和异步任务进行实例新增的集群同步,而当时那个新增逻辑对应的Task类型也是DistroDelayTask,我们这里十一样的
也就是说,我们后面的处理也就是和新增微服务集群同步一样,被异步任务消费,在NacosDelayTaskExecuteEngine 类的 processTasks() 方法中被消费 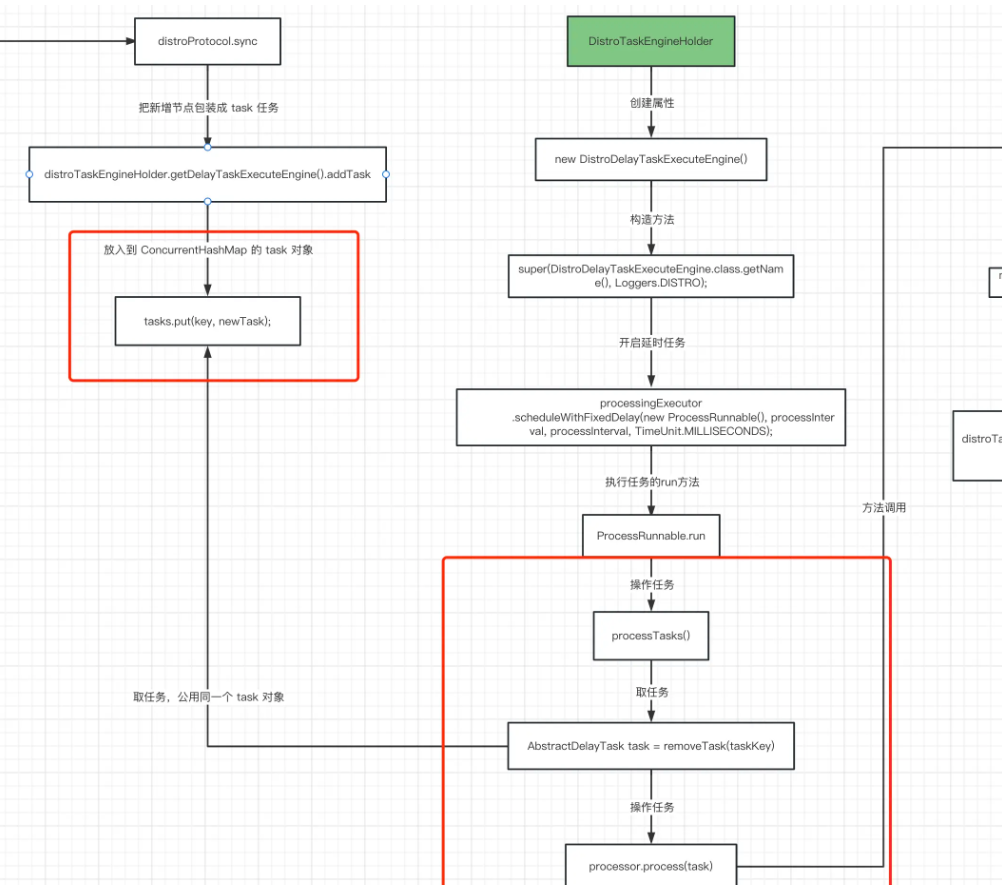
在processTasks()方法中调用DumpAllpRrocessor类下process(),最终会分页查询数据库最新的配置,然后持久化到磁盘上,集群数据就同步完成了。
总结
Nacos 1.4.1 配置中心数据变更同步集群节点的整体逻辑可总结如下:当在 Nacos 控制台或通过 API 变更配置后,发起变更的主节点会先执行原子性数据库操作:一方面更新 config_info 主表(存储最新配置内容),另一方面插入 config_info_history 表(记录配置变更历史,包含变更前内容、操作人、时间戳等),确保配置数据与历史轨迹的一致性。
随后,主节点通过 事件发布 - 监听机制 触发集群同步:由 ConfigChangePublisher 发布 ConfigDataChangeEvent(配置变更事件),AsyncNotifyService 作为该事件的核心监听器,会响应事件并启动集群同步流程 —— 它会从集群成员列表中筛选健康节点,通过 HTTP 协议向其他节点发送同步请求(请求携带 dataId、group、tenant、lastModified 等关键标识,用于精准定位变更配置)。
其他集群节点收到同步请求后,会根据请求中的配置标识精准查询数据库中对应配置的最新数据(而非 “分页查询”,因同步的是单个变更配置,无需批量分页),验证数据版本一致性后,将最新配置内容持久化到本地磁盘(生成对应的配置文件)。
之所以需要持久化到本地磁盘,核心原因是 Nacos 采用 “读写分离” 的性能优化策略:客户端获取配置的读请求,会直接读取本地磁盘缓存的配置文件,而非每次查询数据库 —— 这既能大幅降低数据库访问压力,又能提升配置查询的响应速度。这一设计在之前的源码分析中已验证,本地磁盘文件会通过定时校验与数据库保持一致性,确保数据准确。
通知客户端配置文件变更
代码分析
我们回头来看LongPollingService中对于onEvent()方法的实现,可以看到是将入参event封装为了DataChangeTask,传入ConfigExecutor.executeLongPolling方法中进行处理
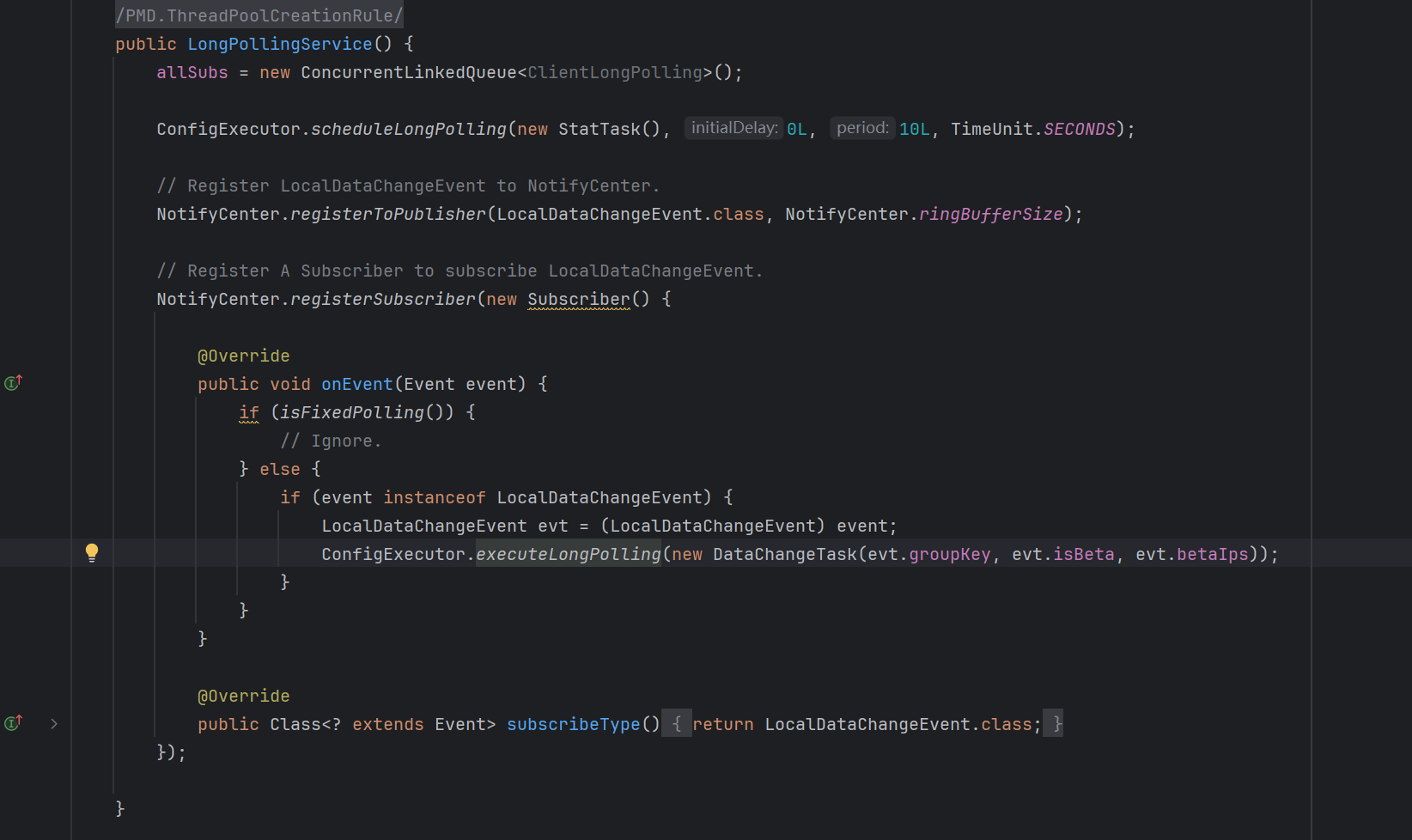
然后我们查看DataChangeTask这个任务类的run()方法
@Override
public void run() {
try {
// 获取当前变更配置的 Beta 环境 MD5(用于 Beta 灰度发布校验)
ConfigCacheService.getContentBetaMd5(groupKey);
// 遍历所有挂起的长轮询客户端(使用 Iterator 支持边遍历边删除)
for (Iterator<ClientLongPolling> iter = allSubs.iterator(); iter.hasNext(); ) {
ClientLongPolling clientSub = iter.next();
// 1. 校验客户端是否订阅了当前变更的配置(groupKey = dataId + group + tenant)
if (clientSub.clientMd5Map.containsKey(groupKey)) {
// 2. Beta 灰度发布过滤:仅通知 Beta IP 列表中的客户端
if (isBeta && !CollectionUtils.contains(betaIps, clientSub.ip)) {
continue; // 非 Beta 客户端跳过,不通知
}
// 3. 配置标签过滤:仅通知订阅匹配 Tag 的客户端
if (StringUtils.isNotBlank(tag) && !tag.equals(clientSub.tag)) {
continue; // Tag 不匹配跳过,保证精准通知
}
// 4. 记录客户端 IP 最新活动时间(用于 IP 白名单/健康度管理)
getRetainIps().put(clientSub.ip, System.currentTimeMillis());
// 5. 移除当前客户端订阅关系:避免重复通知(长轮询请求处理完成)
iter.remove();
// 6. 日志记录:监控通知耗时、客户端信息、配置标识等
LogUtil.CLIENT_LOG.info(
"{}|{}|{}|{}|{}|{}|{}",
(System.currentTimeMillis() - changeTime), // 配置变更到通知的耗时
"in-advance", // 通知类型:提前通知(非超时)
RequestUtil.getRemoteIp((HttpServletRequest) clientSub.asyncContext.getRequest()), // 客户端 IP
"polling", // 请求类型:长轮询
clientSub.clientMd5Map.size(), // 客户端订阅的配置总数
clientSub.probeRequestSize, // 请求体大小
groupKey // 变更的配置标识
);
// 7. 核心操作:主动响应客户端,通知配置变更
clientSub.sendResponse(Arrays.asList(groupKey));
}
}
} catch (Throwable t) {
// 异常捕获:避免单个客户端处理失败导致整体通知流程中断
LogUtil.DEFAULT_LOG.error("data change error: {}", ExceptionUtil.getStackTrace(t));
}
}
通过分析run中的逻辑可以看到,这段代码是配置变更后主动通知长轮询客户端的核心逻辑,属于客户端长轮询机制的 “触发响应” 环节。在代码逻辑上,也通过Beta字段实现灰度发布机制,利用Tag标记支持多维度的隔离。clientSub.sendResponse(Arrays.asList(groupKey)) 通过 AsyncContext 主动结束挂起的 HTTP 请求,向客户端返回变更的 groupKey 列表;客户端收到响应后,会立即发起请求拉取最新配置内容。
总结
可以看到,集群节点中通知客户端变更的操作和我们上一节说到的客户端感知配置变更,实际上是一套机制。可以看到,配置变更,客户端那边利用长轮询机制进行请求从而保证感知到配置的修改,服务端这边会对每个监听者(客户端那边会利用dateId,groupId等信息注册监听者,包含回调逻辑,不记得的可以看上一节)主动触发响应机制,从这里可以看到Nacos1.4.1配置变更的推拉结合的通知机制
客户端的 “拉”:长轮询是 “主动请求等待”,客户端的长轮询(Long Polling)本质是一种 “带等待的拉取”:
-
客户端发起 HTTP 请求到服务端,明确要求 “获取我订阅的配置是否变更”;
-
服务端收到请求后,不会立即返回(不像短轮询那样马上响应),而是将请求挂起(封装为
ClientLongPolling放入allSubs队列),默认挂起 30 秒; -
若 30 秒内没有配置变更,服务端会返回空响应,客户端收到后立即重新发起长轮询(持续 “拉取”);
-
若 30 秒内配置发生变更,服务端会主动结束挂起,返回变更信息(这就是 “推” 的触发)。
服务端的 “推”:配置变更时主动 “唤醒” 长轮询,今天这篇的内容就是服务端 “推” 机制的核心:
-
当配置变更时,服务端发布
ConfigDataChangeEvent事件,触发这段代码的run方法; -
服务端遍历所有挂起的长轮询请求(
allSubs队列),筛选出订阅了该变更配置的客户端; -
通过
clientSub.sendResponse(...)主动结束长轮询挂起,向客户端返回变更通知(相当于 “推” 给客户端)。
通过这种长轮询的推拉结合的设计方式,可以最大程度的减少资源开销(无变更的时候会挂起一段时间),保证低延迟(变更后立马触发响应)以及高可靠性(空响应或者断开后,客户端主动进行重新连接,服务端不需要维护长连接)
文章标题:Nacos源码学习计划-Day18-配置中心-集群-集群节点间如何同步配置信息
文章链接:https://www.zealsinger.xyz/?post=44
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议,转载请注明来自ZealSinger !
如果觉得文章对您有用,请随意打赏。
您的支持是我们继续创作的动力!

微信扫一扫

支付宝扫一扫